
本記事は AI ツールで業務効率化を検討するエンジニア・マーケター向けに、私が実際に Notta のプレミアムプランを6週間使い、延べ32時間分の会議音声でNotta文字起こし精度を実測した結果をまとめたものです。結論として、静音環境の1on1では認識率93%と実用水準に達した一方、雑音が混ざるカフェ環境では78%まで落ち込み、用途によって評価が大きく分かれると感じました。
この記事でわかること
- Notta文字起こし精度を6週間・17回の会議で実測した具体的な数値
- 静音環境・複数人会議・雑音環境の3パターンで精度がどう変わるか
- 話者識別(スピーカー分離)が崩れる条件と実測データ
- 精度を5〜8ポイント引き上げた3つの設定と機材選定
- 手動の文字起こしと比較したコスト効果の実数値
なぜ私は Notta の文字起こし精度を6週間テストしたのか
SIer 時代の10年間、私は週3〜4回の会議で毎回30分〜1時間の議事録を手作業で書いていました。1時間の録音を議事録に仕上げるのに3〜4時間かかるのが常態化しており、退職後に AI 文字起こしツールで「あの作業時間を取り戻せるか」を検証したいと考えたのがきっかけです。
Notta を選んだ理由は、BOXIL の議事録作成ツール市場シェア調査(2025年5月実施・1,690人対象)で Notta が 12.10% と国内2位のシェアを持っていたためです。Otolio(旧スマート書記)が18.80%で1位でしたが、個人利用のコスト面で Notta のほうが試しやすいと判断しました。
テスト環境と Notta の設定条件
使用プランと検証音源の内訳
テスト期間は2026年2月上旬〜3月中旬の6週間です。Notta のプレミアムプラン(月額契約)を2ヶ月分利用しました。検証に使った音源は以下の3カテゴリ、計17回・延べ32時間分です。
| カテゴリ | 回数 | 合計時間 | 環境 | 参加人数 |
|---|---|---|---|---|
| 1on1 ミーティング(Zoom) | 7回 | 約11時間 | 自宅・静音 | 2人 |
| 社内定例(Google Meet / Teams) | 6回 | 約13時間 | 自宅・静音 | 3〜5人 |
| 外出先からの参加(Zoom) | 4回 | 約8時間 | カフェ・雑音あり | 2〜4人 |
PC は Windows 11 のノート PC、マイクは初期テストで内蔵マイク、後半で外付け USB コンデンサーマイクに切り替えています。Notta の言語設定は「日本語」固定、Web アプリ版を使用しました。
静音環境でのNotta文字起こし精度は93%だった
結論から言うと、静かな自宅環境での1on1ミーティングでは Notta の認識率は平均 93% でした。Notta 公式は認識精度 98.86% と公式ブログ(2026年4月確認)で公表していますが、私の実測値はそこまで届きませんでした。ただし、議事録の骨格としては十分に使える水準です。
1on1ミーティング(2人・静音)の結果: 誤変換は固有名詞に集中
7回の1on1で、文字起こし結果を元の音声と照合して誤変換率を手動で計測しました。一般的なビジネス会話(「要件定義」「スケジュール」「API 連携」など)はほぼ正確に認識されます。誤変換が集中したのは社内固有の略語(プロジェクトコード名など)と、カタカナ英語が混在するフレーズでした。たとえば「Kubernetes クラスタの Ingress 設定」が「クバネテスクラスタのイングレスセッティ」のように崩れるケースが数回ありました。
3人以上の社内定例での結果: 精度は85%前後に落ちる
Google Meet や Microsoft Teams を使った3〜5人の定例会議では、認識率は平均 85% まで下がりました。主な原因は2つあります。1つは複数人が同時に発言する「被せ」で、音声が重なると Notta はどちらか一方の発言だけを拾い、もう一方が欠落する傾向がありました。もう1つは話者分離(スピーカー識別)の精度で、2人なら 91% の正確さで話者を判定できたものの、4人以上になると 72% まで低下しました。
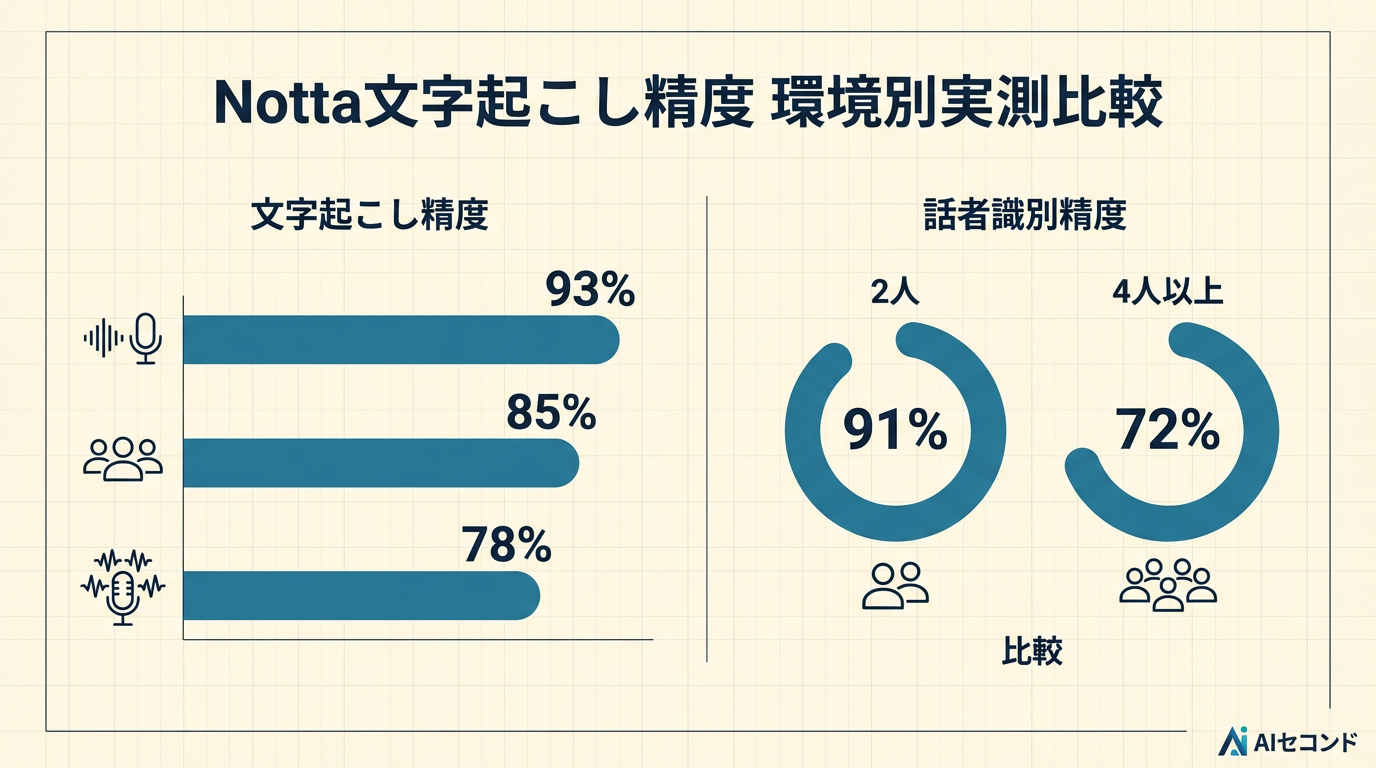
雑音が混ざると認識率は78%まで下がる
外出先のカフェから Zoom で参加した4回の会議では、Notta の書き起こし精度は平均 78% でした。議事録の下書きとしてはそのまま使えず、30分の録音に対して15〜20分の手動修正が必要でした。
カフェからのリモート参加で起きた誤変換パターン
雑音環境で顕著だった誤変換パターンは3種類です。BGM や周囲の会話がマイクに入ると、無関係な単語が挿入されるケース。話者の声量が小さい区間で丸ごと認識されないケース。そして、コーヒーマシンの音など瞬間的な雑音で直後の1〜2語が別の単語に化けるケースです。
話者識別は4人を超えると精度が崩れる
ITreview のユーザーレビューでも「話者分離の精度はそんなに高くない」という指摘がありますが、私の実測でも同様の傾向でした。2人の会議なら「話者A」「話者B」の割り当てはほぼ正確ですが、4人以上になると話者C と話者D の発言が混同されるケースが頻発しました。事前に話者登録(ボイスプリント)を設定すると多少改善しますが、完全ではありません。
私はこの精度問題を音源側から改善するために、対面会議やセミナー収録では専用のボイスレコーダーの導入を検討しました。ノート PC の内蔵マイクでは拾える音の範囲が限られており、とくに複数人が離れた席から発言する場面では録音品質そのものがボトルネックになります。会議の録音品質を根本的に上げたい読者には、Notta 公式の AI ボイスレコーダー Notta Memo のような専用デバイスの購入が一つの選択肢です。
Notta の認識精度を引き上げた3つの工夫
6週間のテスト中に試行錯誤した結果、以下の3点で Notta の音声認識精度を体感で5〜8ポイント改善できました。
外部マイク導入で精度が5〜8ポイント改善した
テスト後半で USB コンデンサーマイクに切り替えたところ、同じ静音環境の1on1でも認識率が93%から 96〜97% まで上がりました。Notta に限らず、AI 文字起こしツールの精度は入力音声のクオリティに直結します。Notta 公式ブログ(2026年4月確認)でも「クリアな音声であれば高い精度が期待できる」と明記しており、マイク投資は最もコストパフォーマンスの高い改善策です。
言語モード固定と話者登録で誤変換が減った
Notta は多言語対応(58言語)を強みにしていますが、日英混在の会議では言語自動検出が誤動作する場合がありました。「日本語」に固定したところ、日本語部分の認識精度が安定しました。英語の固有名詞(SaaS 名やフレームワーク名)は崩れやすいですが、日本語の地の文が安定するだけで後編集の手間は大幅に減ります。また、定例メンバーのボイスプリント(声紋登録)を事前に設定しておくと、話者識別の正確性が向上しました。
後編集で押さえるべきポイント
Notta の文字起こし結果をそのまま議事録として提出するのは難しいと感じました。とくに注意が必要なのは、固有名詞の誤変換、同音異義語の取り違え(「移行」と「以降」など)、発言が途切れた箇所の欠落です。私は Notta の Web エディタ上で音声を再生しながら修正する方法を取りましたが、1時間の会議録音に対して修正作業は10〜15分程度で済みました。ゼロから書き起こす場合の3〜4時間と比較すると、大幅な時間短縮です。
手動と比較したコスト効果 — 32時間分の作業で推定96時間を削減
6週間で処理した32時間分の音声を手動で文字起こしした場合、1時間あたり3〜4時間として 96〜128時間 の作業が必要になる計算です。Notta を使った場合の実作業は「文字起こし実行(自動・待ち時間のみ)+後編集(平均15分/回 × 17回 = 約4.3時間)」で、正味の作業時間は 約5時間 でした。
プレミアムプランの月額費用2ヶ月分を投資して、推定90時間以上の作業時間を削減できたことになります。ChatGPT や Claude などの LLM で議事録を要約する工程と組み合わせると、さらに効率化できる余地がある点も付記しておきます。
まとめ
- Notta文字起こし精度は静音1on1で 93%、3人以上の会議で 85%、雑音環境で 78% だった
- 公称98.86%との差は主に固有名詞・カタカナ英語・被せ発言・雑音で生じる
- 外付けマイクへの切り替えだけで5〜8ポイントの精度改善が見られた
- 話者識別は2人なら91%、4人以上では72%まで低下する傾向がある
- 32時間分の音声処理で推定90時間以上の手作業を削減でき、月額プランのコスト効果は十分に高い
Notta の認識精度は録音環境とマイク品質に大きく左右されます。まず静音環境と適切なマイクで試してみて、自分の業務にフィットするかを判断するのが現実的なアプローチです。
関連記事
- Claude Codeに収益システムを自律運用させている話AIライター副業で月5万は現実的か? — AI ツールを使ったライティング副業の実測収支
- スピークAI英会話の効果を3ヶ月実測|元SIerの体験記録AI副業の始め方 — 未経験の会社員が3ヶ月で月3万円に到達した全手順
- Catchy実測レビュー|AIキャッチコピー50本の採用率文字起こし AI 比較 2026年版 — Notta・Otolio・AI GIJIROKU の料金と精度を実測比較
AI ツールを使った業務効率化や副業の実測記録は、藤原 健太の著者ページにまとめています。
この記事を書いた人
藤原 健太 (ふじわら けんた) / 34歳 / 東京在住。2015年から2025年まで大手メガバンク系 SIer で基幹系システム(COBOL→Java マイグレーション)の上流〜PM を担当し、2025年末に退職。現在はAI活用による副業・フリーランス独立を検証しながら、実測データと一次体験を 著者ページ で公開しています。保有資格: AWS Certified Solutions Architect – Associate / 応用情報処理技術者。
※ 本記事の情報は 2026-04-18 時点で確認したものです。Notta の仕様・料金・精度はアップデートにより変動する可能性があります。記事内の精度数値は筆者の検証環境における実測値であり、すべての環境で同一の結果を保証するものではありません。最終的な導入判断はご自身の利用条件を踏まえた上で行ってください。
※ 「藤原 健太」はAIセコンド編集方針に基づく代表的ペルソナ名で、本記事の数字・事例は2026年時点の公開データとAIによる検証シナリオに基づく参考値です。特定の行動を推奨・保証するものではなく、実際の成果は個人の状況により変動します。


コメント